Del 30 de Marzo al 3 de Abril de 2020 se ha celebrado el congreso «The 35th ACM/SIGAPP Symposium On Applied Computing» en el que el grupo Absys ha presentado el trabajo «Profiled glucose forecasting using genetic programming and clustering». El artículo ha sido seleccionado para publicar una versión extendida en Applied Soft Computing Journal.
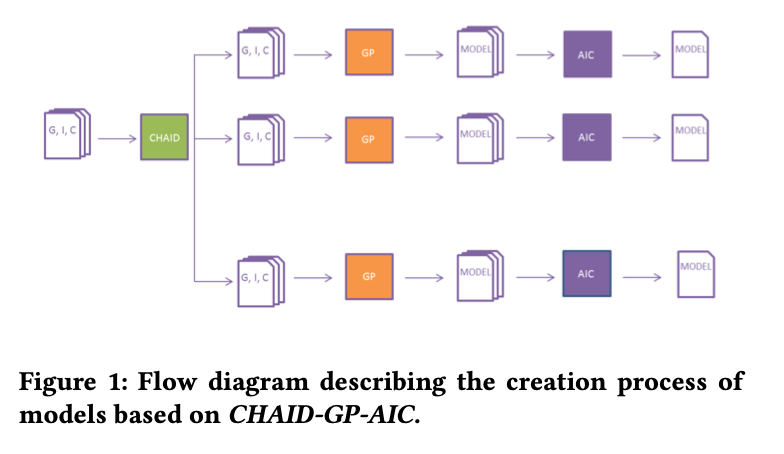
Resumen: En este trabajo se propone un método para obtener previsiones precisas de los valores de glucosa subcutánea de los pacientes diabéticos. Se aplican técnicas estadísticas para identificar situaciones cotidianas de comportamientos de la glucosa y descubrir perfiles de glucosa. Este conocimiento se utiliza para crear modelos predictivos con programación genética. Las series temporales de los valores de glucosa, medidos mediante sistemas de monitorización continua de la glucosa, se dividen en intervalos de 4 horas, no superpuestos, y se agrupan mediante una técnica basada en árboles de decisión llamada detección automática de interacción chi-cuadrado. Los perfiles de glucosa se clasifican utilizando las variables de decisión a fin de personalizar los modelos para los diferentes perfiles. Los modelos de programación genética creados con los valores de glucosa del conjunto de datos original se comparan con los de los modelos creados con valores de glucosa clasificados. Se observan diferencias y asociaciones significativas entre los perfiles de glucosa. En general, el uso de modelos de glucosa perfilados mejora la precisión de las predicciones con respecto a las de los modelos creados con el conjunto de datos original.
Abstract: This paper proposes a method to obtain accurate forecastings of the subcutaneous glucose values from diabetic patients. Statistical techniques are applied to identify everyday situations of glucose behaviors and discover glucose profiles. This knowledge is used to create predictive models with genetic programming. The time series of glucose values, measured using continuous glucose monitoring systems, are divided into 4-hour, non-overlapping slots and clustered using a technique based on decision trees called chi-square automatic interaction detection. The glucose profiles are classified using the decision variables in order to customize the models for different profiles. Genetic programming models created with glucose values from the original dataset are compared to those of models created with classified glucose values. Significant differences and associations are observed between the glucose profiles. In general, using profiled glucose models improves the accuracy of the predictions with respect to those of models created with the original dataset.